| Простое объяснение CRC. |
|
Это небольшое вступление посвящено, объяснению причин побудивших меня написать эту статью. Те, кто ценят свое время, могут пропустить эту главу и сразу перейти к следующей. Некоторое время назад я решил разобраться в том, что же такое CRC, и как его можно рассчитать. Естественно, в первую очередь я зашел на поисковый сервер и попробовал найти все что возможно. Все мои поиски свелись к двум статьям (они приведены в конце) и, как ни странно выдержкам из этих статей. В принципе содержания этих документов более чем достаточно для ответа на вышеуказанные вопросы. Но то, что очевидно для программиста профессионала далеко не всегда понятно программисту любителю. Возможно эти статьи могут кому-нибудь показаться сложными для понимания. Так что, я поставил перед собой цель написать собственное объяснение, которое, надеюсь, будет понятно всем. Я заранее приношу свои извинения автором этих документов, эа то, что позволю себе иногда цитировать их. Применение CRCПрежде всего, определим, зачем нам может потребоваться вычислять CRC? Мне видятся следующие причины: Не раз мне приходилось наблюдать, как на пораженном вирусом компьютере отказывались запускаться некоторые программы. Перед запуском они рассчитывали CRC своего кода и, если результат не совпадал с эталоном (спрятанным, кстати, чаще всего внутри этого кода) они выдавали сообщение о том, что их код был изменен и, чаще всего отказывались работать. Такое поведение программы, на мой взгляд, является очень актуальным в наше время. Между прочим, расчет CRC, в какой-то мере усложняет жизнь взломщикам защит, если программа, конечно, ее имеет. Если Вам необходимо быть уверенным в достоверности каких-либо данных, CRC может помочь и здесь. Вы можете, например, вычислить CRC файла данных, или потока данных переданных, допустим, через какой-либо канал связи. Этот список легко продолжить ┘ Вычисление CRCВполне естественным может показаться решение выполнить над данными какое-нибудь математическое действие, и результат этого действия объявить как CRC. Это действие должно удовлетворять следующему правилу: Любое изменение данных, пусть даже незначительное, (например: изменение всего одного байта) должно, с почти 100% вероятностью, влиять на величину нашего результата. Такое действие, как, например, сложение, не выдерживает никакой критики. Любая перестановка байт даст в результате - тот же самый результат. Было установлено, что самым оптимальным действием является - деление. Итак, для того, чтобы вычислить CRC представим файл или любой другой набор данных как большое бинарное число. Назовем этот набор данных делимым. Выберем делитель. Кстати, в зависимости от размера делителя (размер обозначают буквой W) говорят, что имеют дело, например с CRC16 или CRC32. Вы, наверное, догадываетесь, что подобные популярные размеры делителей не случайны, все они кратны байту. Давайте условимся называть их CRC полиномами, а еще лучше просто полиномами. Наш набор данных будем называть сообщением. Значение полинома для нас не безразлично, так как бывают как более, так и менее "удачные" значения. Но оставим математикам выбор наиболее оптимальных значений полиномов, к тому же они уже давно это сделали за нас.
Деление в CRC арифметике отличается от классического деления. Ни каких заимствований из старших разрядов, переносов и проч. Все сводится к известной операции XOR (Исключающее ИЛИ). Напомню, что в результате XOR операции между парой битов - "1" получается лишь в случае, если биты участвующие в операции различны:
Небольшое уточнение: Когда говорят что полином 32-разрядный (W=32) , то это означает, что его размер 33 бита, причем старший бит обязательно равен "1" и остается как бы за кадром. В результате операции деления сообщения на полином мы получим результат (который нас НЕ интересует) деления, и остаток -> CRC.
Давайте разберем простейший пример:
Здесь следует добавить, что сообщение должно быть дополнено нулями, причем число нулей W-1. Это вызвано необходимостью "пропустить" все сообщение через XOR с полиномом
Для начала разделим наше сообщение на полином дедовским способом - в столбик.
11011 / 01010000 \ 0110 (результат деления, который нам пополам)
11011
--------
011110
11011
---------
1010 -> остаток (CRC)
Еще раз позволю себе заметить, что все действия вычитания заменяются операцией XOR.
Давайте теперь посмотрим на этот пример с точки зрения программирования.
Допустим, у нас есть 4-х битный регистр, через который мы бит за битом будем протягивать наше сообщение справа налево. То есть за одну операцию сдвига каждый бит сдвигается на одну позицию влево. Крайний правый бит - нулевой и является самым младшим.
Загрузим наше сообщение в регистр. Естественно наше дополненное нулями сообщение не поместится в нем целиком. Но это не должно нас волновать. Наше сообщение будет, как поезд из тоннеля, сдвигаться справа налево бит за битом, до тех пор, пока крайний левый бит, только что покинувший регистр не станет равным единице. Когда это произойдет, мы выполняем операцию XOR текущего содержимого регистра с известным нам полиномом. Не забудьте, что единичный выдвинутый бит при операции XOR складывается со старшим битом полинома, который тоже остается как бы за кадром.
Чтобы не быть голословным приведу следующий пример, который выполняет ту же самую операцию, что и старое как мир деление в столбик с теми же данными, но с точки зрения программиста. Делимое (сообщение) пропускают через регистр бит за битом справа налево. Когда из регистра уходит единица выполняется XOR содержимого регистра с полиномом.
0101 0000 // Исходное сообщение дополненное нулями
<< 1010 0000 // Сдвигаем биты влево на одну позицию (shl reg,1
// в ассемблере), так как выдвигается нуль то операция
// XOR не выполняется.
<< 0100 0000 // Очередной сдвиг и так как влево ушла единица то XOR
XOR 1111 0000 // результат операции XOR
<< 1110 0000 // еще один сдвиг и так как опять ушла единица - XOR
XOR 0101 0000 // результат операции XOR
<< 1010 0000 // последний сдвиг, и так как ушел нуль то XOR больше не делаем.
Итак, остаток от деления снова 1010. Обратите внимание, на то, что обе процедуры равнозначны. Разве что при делении в столбик старшую единицу полинома уже нельзя держать в уме.
Теперь выполним следующую операцию:
Вспомните, что мы как бы прикладывали полином к сообщению, а затем выполняли операцию XOR, затем полученный результат опять подвергали операции XOR с тем же полиномом, но уже сдвинутым вправо относительно старшего бита сообщения. Итак, в нашем последнем примере мы видим, что операция XOR выполнялась дважды, и что во второй раз полином был сдвинут относительно старшего бита сообщения на одну позицию.
Выполним операцию XOR между полиномом и им же самим, но смещенным на один бит вправо.
110110 XOR 011011 --------- 101101 (╧1) // Этот результат очень важен ! И вот почему. Если выполнить операцию XOR (╧1) с нашим исходным сообщением, то мы получим тот же остаток. 1010 Все это естественно не случайно, а является следствием определенных свойств операции XOR. Что это нам дает? В первую очередь это возможность упростить наш алгоритм. Во-первых, это слишком дорогое удовольствие протягивать сообщение, размер которого может быть очень большим, бит за битом. Мы можем выдвигать сразу группу бит, например байт. И это очень удобно. Представим себе, что регистр 32-разрядный. И выдвигаем мы не бит, а байт. Этот 1-й байт как раз и будет тем правилом, по которому мы можем заранее рассчитать (╧1). Байт это всего-навсего 256 допустимых комбинаций, и следовательно мы можем заранее рассчитать (╧1) при любых значениях управляющего байта. Причем полином должен быть заранее определен и не подлежит изменению. Старший байт сообщения является управляющим, он показывает нам сколько раз и с каким смещением наш полином должен будет подвергнут операции XOR сам с собой, но с разным смещением, чтобы в результате получилось (╧1). Если Вы все-таки не уловили суть, попробуйте перечитать статью до этого места.
Но что значит "поможет рассчитать"?
for (int bx=0; bx<256; bx++){
int eax=0;
eax=eax&0xFFFFFF00+bx&0xFF;
for (int cx=0; cx<8; cx++){
if (eax&&0x1) {
eax>>=1;
eax^=poly;
}
else eax>>=1;
}
crctable[bx]=eax;
}
Так что видите все не так уж и страшно. 1-й выдвинутый байт сообщения будет являться индексом в нашей CRC таблице. Останется лишь выполнить XOR табличного значения с текущим значением регистра. Алгоритм примерно такой: До тех пор пока все сообщение не обработано Выдвигаем 1-й байт сообщения из (допустим 32-разрядного) регистра Используя байт как индекс, в CRC таблице вытаскиваем из нее значение Выполняем XOR этого значения с текущим значением регистра Вариант на мето-языке While(В строке имеются необработанные биты) Begin Top = top_byte of register; Register = (сдвиг register на 8 бит влево) OR (новые биты из строки); Register = Register XOR табличное значение [top]; End; Прямой табличный алгоритмОписанный выше алгоритм, безусловно, правилен, но не оптимален. Увы, но я так и не смог уловить, как из выше описанного алгоритма удалось получить представленный ниже. Но можно не сомневаться в его истинности. 
Казалось бы, сейчас мы имеем дело с законченной формулой расчета. Но, увы, мы живем в реальном мире, и это еще не все. Благодаря существованию микросхемы UART (последовательный ввод / вывод) этот алгоритм претерпел изменения. Дело в том, что эта микросхема передает байты начиная с наименее значащего бита, то есть, в зеркальном порядке. Правда, сами байты обрабатываются в естественном порядке. Собственно, мы могли бы сами взять на себя обязанность "переворачивать" байты перед их обработкой, но было принято решение перестроить наш алгоритм. 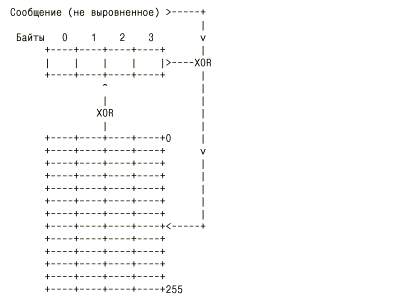
Итак, последовательность действий: 1. Сдвигаем регистр на один байт вправо. 2. XOR только, что выдвинутого байта с текущим байтом сообщения. Результатом будет смещение в CRC таблице. 3. XOR значения из таблицы с содержимым регистра. 4. Если сообщение обработано не до конца, то снова п.1 Реализация этого алгоритма на Ассемблере представлена ниже. CX - длина сообщения EAX - текущее значение CRC DS:SI - указатель буфера, содержащего наше сообщение. crctable - заранее рассчитанная таблица CRC. computeLoop: xor ebx, ebx xor al, [si] mov bl, al shr eax, 8 xor eax, dword ptr[4*ebx+crctable] inc si loop computeLoop xor eax, 0FFFFFFFFh
Последняя строка не случайна. Так как в существующих алгоритмах расчета, сначала в регистре (в котором будет содержаться текущее значение CRC) выставляют начальное значение, а затем по окончании вычислений содержимое регистра опять подвергают операции XOR с определенным значением.
Вы можете так же воспользоваться нижеследующим кодом на языке C.
crc32(┘) - ф-ция расчета crc
init_crc32() - ф-ция генерации crc таблицы.
buf - сообщение - файл или блок данных как Вам больше нравится
len - длина этого набора данных.
u_long crc32(u_char *buf, int len) {
u_char *p;
u_long crc;
init_crc32(); /* рассчитаем таблицу */
crc = 0xffffffff; /* начальное значение в регистр */
for (p = buf; len > 0; ++p, --len)
/* не очень удобный для восприятия код расчета crc =) */
crc = (crc << 8) ^ crc32_table[(crc >> 24) ^ *p];
/* вот он, наш crc */
return ~crc; // инвертируем получившееся число.
}
/* Функция расчета crc таблицы */
// Обратите внимание, 0x04c11db7 это один из "удачных" полиномов.
#define CRC32_POLY 0x04c11db7 /* AUTODIN II, Ethernet, & FDDI */
init_crc32() {
int i, j;
u_long c;
for (i = 0; i < 256; ++i) {
for (c = i << 24, j = 8; j > 0; --j)
c = c & 0x80000000 ? (c << 1) ^ CRC32_POLY : (c << 1);
crc32_table[i] = c;
}
}
Очевидно, что при расчете CRC для блока данных у Вас вряд ли возникнет вопрос, где хранить это число (или избыточный код =). Но как быть в случае, когда нам требуется рассчитать CRC для исполняемого файла ? Вы можете оставить в коде программы какой-нибудь маячок - например строковую константу. Причем Вы должны предусмотреть место для CRC в какой-нибудь части этой константы. Затем для удобства можно написать небольшую программу, которая откроет Ваш exe-файл и рассчитает для него CRC. Программа должна будет найти маячок и проигнорировать при расчете байты в которых будет находиться CRC. То есть, если наш полином 16-разрядный, то соответственно, придется пропустить 2 байта, если 32-разрядный - четыре. Когда наша служебная программа дойдет до конца файла, она впишет полученный CRC в то самое место которое мы пропустили при расчете. Вы ведь и сами догадались зачем это было сделано. Ведь если бы мы рассчитали CRC для файла без всяких пропусков, а затем вписали бы в него полученное значение, то CRC тут же бы изменилось. В коде программы, также потребуется найти маячок и проигнорировать при расчете байты содержащие CRC.
Вот собственно и все. Можно добавить лишь следующее. Описанный выше алгоритм базовый и это вовсе не означает, что он должен оставаться неизменным. Включайте Вашу фантазию, тем более, если Вы используете CRC для защиты программ от взломщиков. Так как можно например вычислять CRC не всего файла, а лишь его части, или допустим использовать перекрестный расчет. Из dll вычислить CRC исполняемого файла и наоборот.
1. A painless guide to CRC error detection algorithms
Ross N. Williams
2. CRC and how to Reverse it
Anarchriz/DREAD
|